- Load the R packages we will use
Download \(CO_2\) emissions per capita from Our World in Data into the directory for this post.
Assign the location of the file to
file_csv. The data should be in the same directory as this file
Read the data into R and assign it to emissions
- Show the first 10 rows (observations of)
emissions
slice_head(emissions,n=10)
Entity Code Year Annual.CO2.emissions..per.capita.
1 Afghanistan AFG 1949 0.0019
2 Afghanistan AFG 1950 0.0109
3 Afghanistan AFG 1951 0.0117
4 Afghanistan AFG 1952 0.0115
5 Afghanistan AFG 1953 0.0132
6 Afghanistan AFG 1954 0.0130
7 Afghanistan AFG 1955 0.0186
8 Afghanistan AFG 1956 0.0218
9 Afghanistan AFG 1957 0.0343
10 Afghanistan AFG 1958 0.0380- Start with
emissionsdata THEN
use clean names for the janitor package to make the names easier to work with assign the output to tidy_emissions show the first 10 rows of tidy_emissions
tidy_emissions <- emissions %>%
clean_names()
slice_head(tidy_emissions,n=10)
entity code year annual_co2_emissions_per_capita
1 Afghanistan AFG 1949 0.0019
2 Afghanistan AFG 1950 0.0109
3 Afghanistan AFG 1951 0.0117
4 Afghanistan AFG 1952 0.0115
5 Afghanistan AFG 1953 0.0132
6 Afghanistan AFG 1954 0.0130
7 Afghanistan AFG 1955 0.0186
8 Afghanistan AFG 1956 0.0218
9 Afghanistan AFG 1957 0.0343
10 Afghanistan AFG 1958 0.0380- Start with the
tidy_emissionsTHEN usefilterto extract rows withyear == 2000THEN useskimto calculate the descriptive statistics
| Name | Piped data |
| Number of rows | 228 |
| Number of columns | 4 |
| _______________________ | |
| Column type frequency: | |
| character | 2 |
| numeric | 2 |
| ________________________ | |
| Group variables | None |
Variable type: character
| skim_variable | n_missing | complete_rate | min | max | empty | n_unique | whitespace |
|---|---|---|---|---|---|---|---|
| entity | 0 | 1 | 4 | 32 | 0 | 228 | 0 |
| code | 0 | 1 | 0 | 8 | 12 | 217 | 0 |
Variable type: numeric
| skim_variable | n_missing | complete_rate | mean | sd | p0 | p25 | p50 | p75 | p100 | hist |
|---|---|---|---|---|---|---|---|---|---|---|
| year | 0 | 1 | 2000.00 | 0.00 | 2e+03 | 2000.00 | 2000.00 | 2000.00 | 2000.00 | ▁▁▇▁▁ |
| annual_co2_emissions_per_capita | 0 | 1 | 5.15 | 6.93 | 2e-02 | 0.74 | 2.97 | 7.85 | 57.41 | ▇▁▁▁▁ |
- 13 Observations have a missing code. How are these observations different? start with
tidy_emissionsthen extract rows withyear == 2000and are missing a code
[1] entity code
[3] year annual_co2_emissions_per_capita
<0 rows> (or 0-length row.names)Entities that are not countries do not have country codes
- Start with tidy_emissions THEN
use filter to extract rows with year == 2000 and without missing codes THEN use select to drop the year variable THEN use rename to change the variable entityto country assign the output to emissions_2000
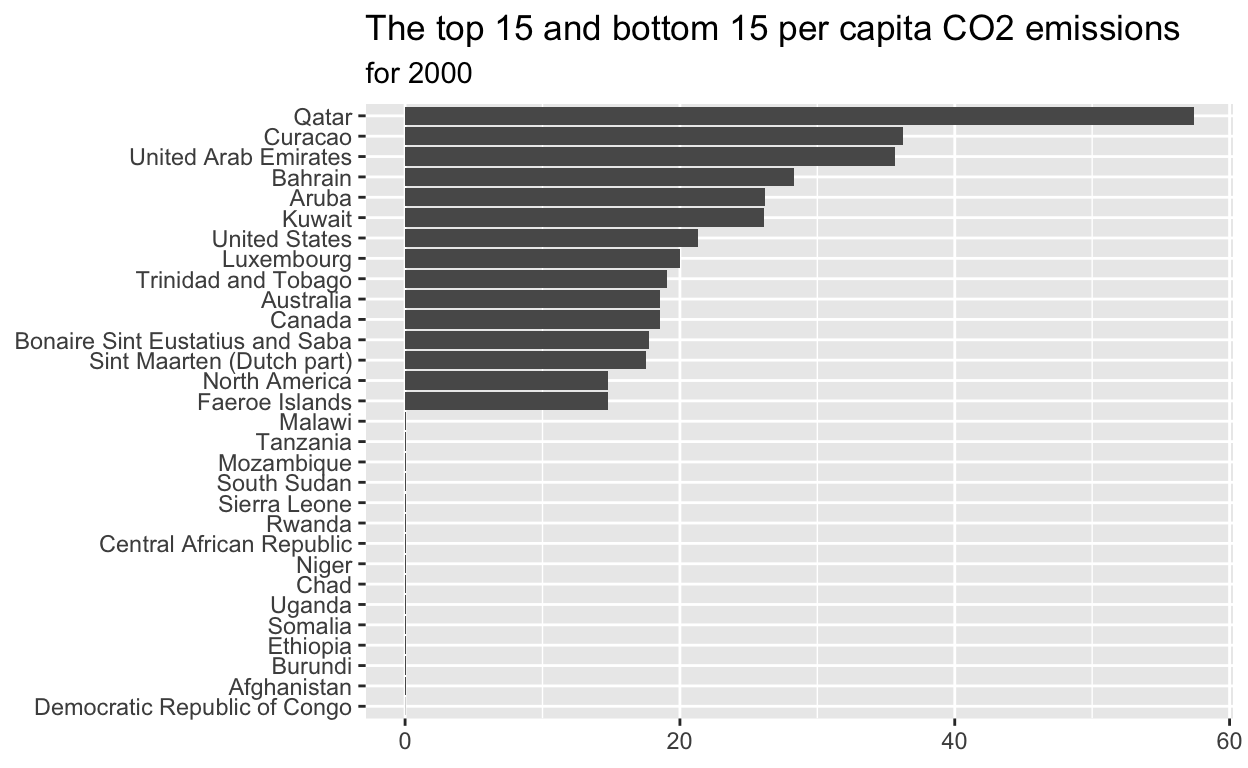
- Which 15 countries have the highest
annual_co2_emissions_per_capita?
Start with emissions_2000 THEN use slice_max to extract the 15 rows with the annual_co2_emissions_per_capita assign the output to max_15_emitters
- Which 15 countries have the lowest
annual_co2_emissions_per_capita?
Start with emissions_2000 THEN use slice_min to extract the 15 rows with the annual_co2_emissions_per_capita assign the output to min_15_emitters
- Use
blind_rowsto bind together themax_15_emittersandmin_15_emittersassign the output tomax_min_15
max_min_15 <- bind_rows(max_15_emitters,min_15_emitters)
- Export
max_min_15to 3 file formats
- Read the 3 file formats into R
max_min_15_csv <-read_csv ("max_min_15.csv") # comma separated values
max_min_15_tsv <-read_tsv ("max_min_15.tsv") # tab separated
max_min_15_psv <-read_delim ("max_min_15.psv",delim = "|") # pipe-separated
- Use
setdiffto check for any difference amongmax_min_15_csv,max_min_15_tsvandmax_min_15_psv
setdiff(max_min_15_csv,max_min_15_tsv,max_min_15_psv)
# A tibble: 0 × 3
# … with 3 variables: country <chr>, code <chr>,
# annual_co2_emissions_per_capita <dbl>Are there any differences?
- Reorder
countryinmax_min_15for plotting and assign to max_min_15_plot_data
start with emissions_2000 THEN use mutate to reorder country according to annual_co2_emissions_per_capita
- Plot
max_min_15_plot_data
ggplot(data=max_min_15_plot_data,
mapping=aes(x=annual_co2_emissions_per_capita,y=country))+
geom_col()+
labs(title="The top 15 and bottom 15 per capita CO2 emissions",
subtitle = "for 2000",
x=NULL,
y=NULL)
17.Save the plot directory with this post
- Add preview.png to yaml chuck at the top of this file
preview: preview.png